Prevent flickering loading animation with XState
Published on
Loading indicators tell users that something is happening and will complete soon. They exist to improve UX, but they can worsen UX if they are directly hidden after underlying HTTP requests resolve. In this article I share XState patterns I used to prevent this issue in our Turing machine visualizer.
This article is the third one of a series about our Turing machine visualizer built with XState .
Loading indicators are necessary for users to know that they are waiting something to happen, and not wasting their time. But bad UX comes when loading indicators are directly bound to HTTP responses, that can come really quickly on a fast network, making loading indicator flicker. Sam Selikoff explains it well in one of his videos, and solves the issue with Promise.all and Promise.allSettled. We’ll solve it with XState!
We are going to dissect the code used by our Turing machine visualizer for its loading animation:
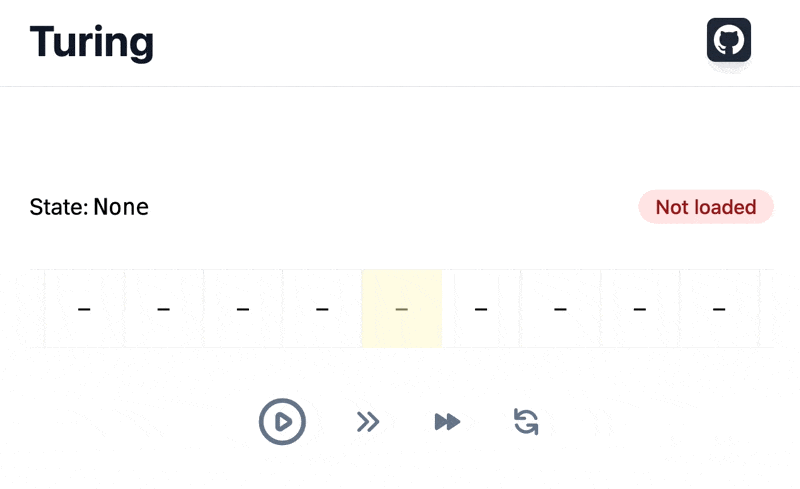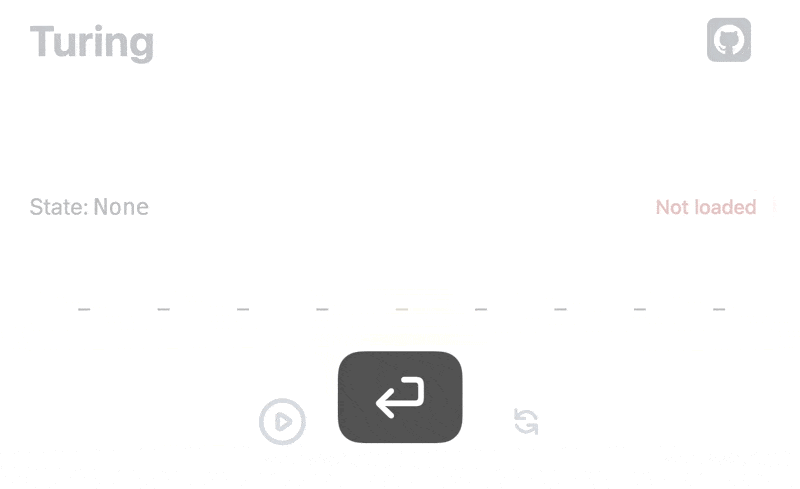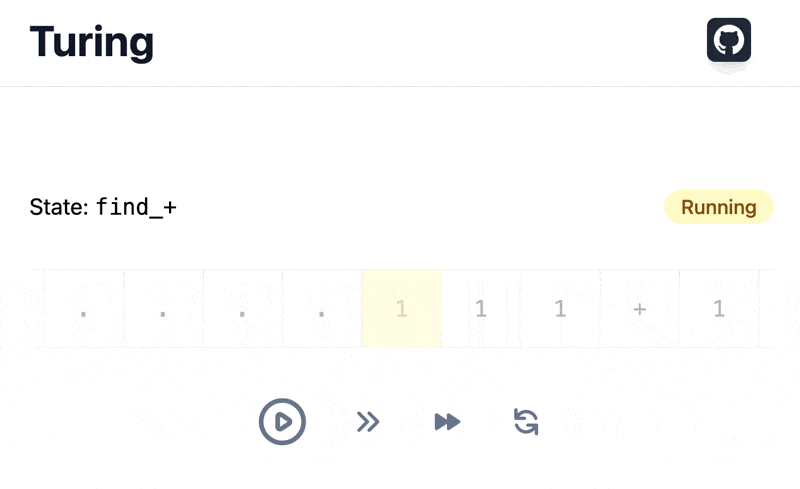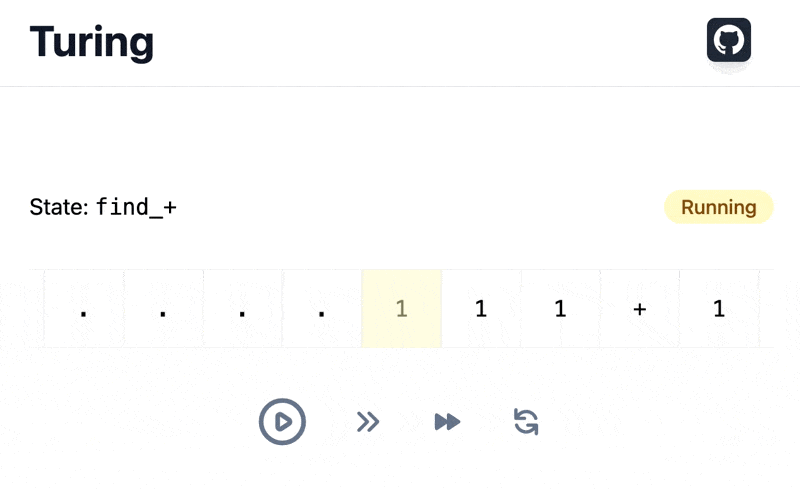
We need to ensure loading state is always displayed enough time for users to see it, understand something is loading, and do not be surprised by a rough disappearing. As for data loading in the previous article, parallel states can help us.
Our objective is to ensure loading animation will always be displayed for at least one second. One second is enough for the animation to be pleasant to the user and not too long neither. But if the network request takes more than one second, we don’t want to artificially delay the loading animation more.
permalinkUse a parallel state to wait for all tasks to finish
In the previous article we orchestrated the request that executes Turing machines server-side. We ended up with this machine, managing visualizer controls and request to server more or less concurrently thanks to a parallel state:
ts
Instead of directly targeting the state that makes the request when receiving a Load event, we target a parallel state:
ts
The machine behaves exactly the same as previously, in a more sophisticated way. We benefit from the fact that when all the orthogonal regions of a parallel state reach a final state, the parallel state is considered to be done and onDone transitions defined on it are tried.
Currently, Executing machine and input only has one orthogonal region (Making request to server), that reaches a final state when request returns, by resolving or rejecting. If the execution fails, we assign a property to context to be able to later know if the execution failed, once the overall parallel state is done. This property is reset before making request.
Think of a parallel state used like this, to wait for several tasks to complete, as a Promise.all that would not know the resolved value of each independent promise; values must be assigned somewhere:
ts
Once all orthogonal regions are done, onDone transitions defined on the parallel state are tried. If Error has occured while sending request returns true, we target the error state (Failed to execute machine with input), otherwise we target the success state (Received response).
The error state (Failed to execute machine with input) can be used to conditionally display the error alert as it used to! (This was a major question in the previous article.)
permalinkShow loading indicator for at least one second
Until now, our modifications were purely stylistic and the overall behavior of the machine did not change.
The last thing to do is to implement the delay of one second:
ts
A timer of one second is started, which then triggers a transition to a final state. The behavior of the parallel state is now to wait for its both orthogonal regions to finish.
If the network is fast, we artificially wait for one second:

If the request fails, we display the error alert only after one second:
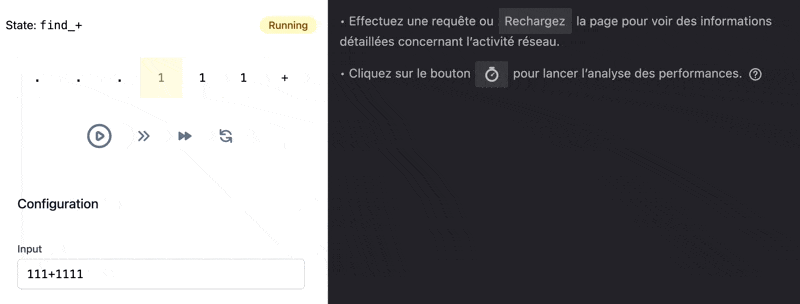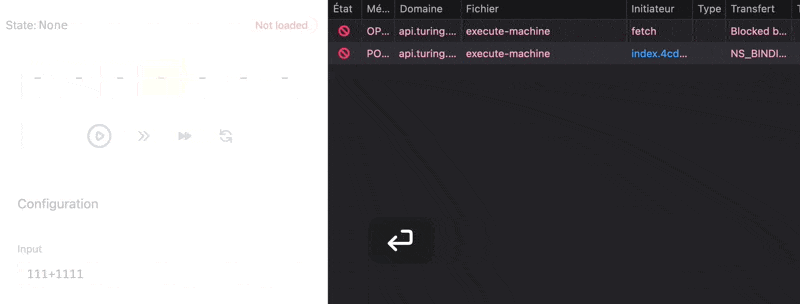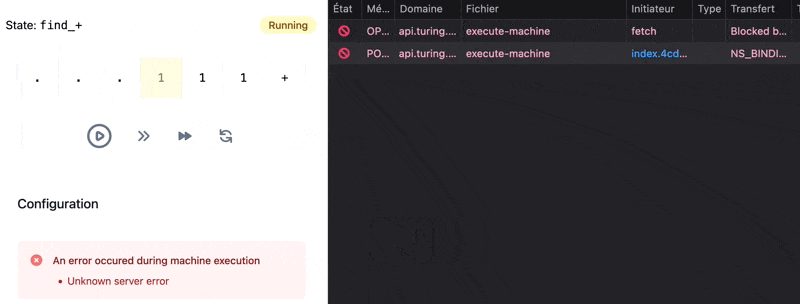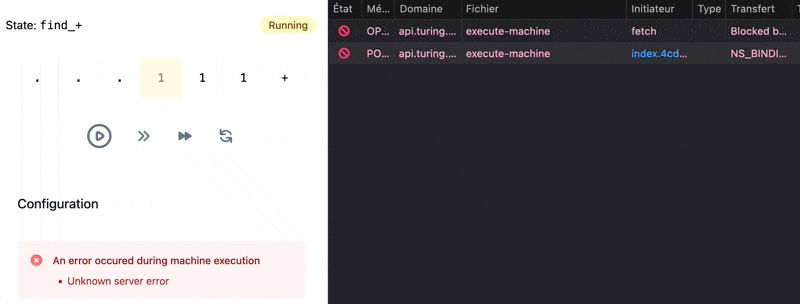
If the network is slow, but the request takes less than one second, we wait a bit artificially to reach one second:
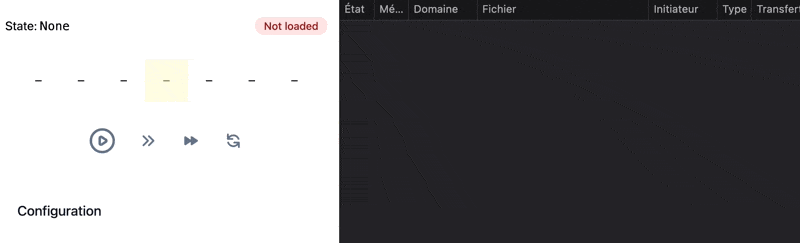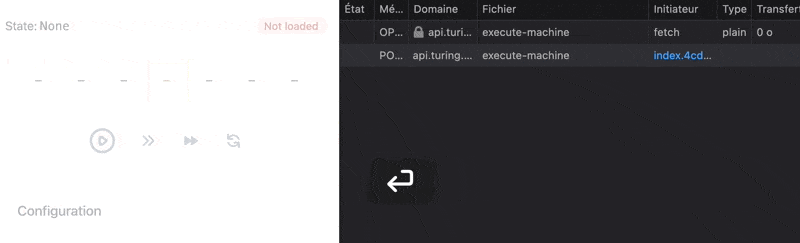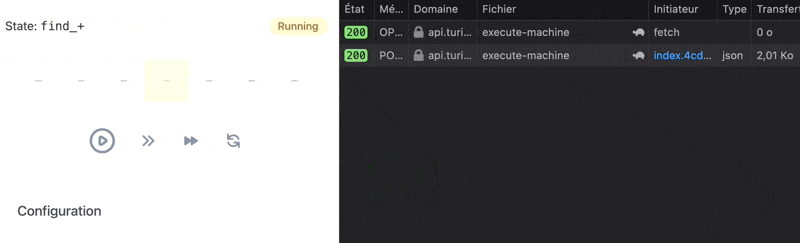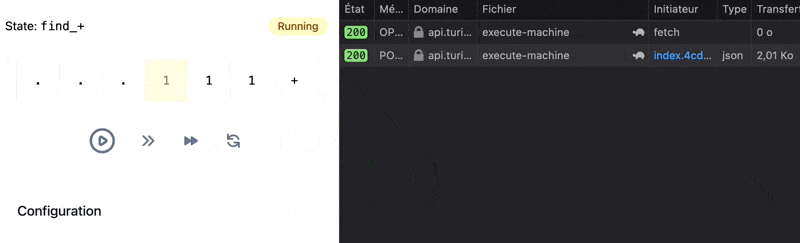
If the network is slow and the request takes more than one second, we do not wait artificially and stop displaying loading indicator when response arrives:
permalinkSummary
Parallel states are one of the most interesting features of statecharts. They provide a lot of flexibility to implement really different use cases. We used them to orchestrate mostly separate behaviors, and here we used them to wait for several tasks to complete.
Loading states on their own are an interesting UI/UX topic. I recorded a video about deferred and cancellable loading states with XState. That covers other questions like: should a loading state be immediately shown? Or should we display it only if network request takes more than X seconds?
So that’s the third article of the series about Turing machine visualizer showcase! Next articles will be released soon.
We’ll talk about a small UI detail that makes a big UX improvement: the stale data indicator of our Turing machine visualizer.
The code of the visualizer is on GitHub.
The series contains the following articles:
- Control tape of Turing machine visualizer with XState
- Orchestrate request for server-side execution of Turing machine with XState
- Prevent flickering loading animation with XState
- Create stale data indicator with XState
- Create a proxy state machine to drive CSS transitions on state changes with XState